

Part 1: Modeling Ambiguity
When you are developing data models for fields in Drupal sometimes the only thing you can count on is that there will be exceptions to the model. Thankfully, with Drupal, you can incorporate a lot of flexibility into your data model. Typically that flexibility comes at the cost of complexity for you, the developer or site builder, and likely, for your content contributors. It gets even more difficult when those fields are irregular in format, need to be responsive, and are a part of a time sensitive content launch involving content experts with little to no Drupal experience.
Recently, we were faced with a situation just like this – we needed a high degree of field flexibility for tabular data that ultimately needed to be responsive and the content contributor experience had to be dead simple. Thankfully the effort spent to develop this solution was rewarded the very first time we were able to reconfigure the field data model on the fly. I’d like to share our approach to the field model and the responsive no-tables end result. In the first part of this two-part series I’ll walk you through the process of modeling fields with a lot of flexibility and in the second part we’ll focus on how to represent that model in responsive design with a “no-tables” strategy.
The problem at hand
Let’s start with a brief overview of the problem. A client was launching a new site with a deadline that required a large content entry effort from a number of Drupal novices. The scale and pacing made it necessary to simplify the entry process as much as possible. In fact, development and content entry needed to occur simultaneously to complete the site by the launch date. Our efforts as a development team were to enable content entry at the earliest date possible and fill out improvements and other functionality after. While much of the content was tabular in nature, individual tables varied occasionally but significantly and there simply was too much of it to audit so that detail was cataloged. Heavy tablet and mobile device use was predicted and so all of the content, including the tables, needed to be responsive.
In summary we needed to:
- preserve and enable content idiosyncrasies
- keep entry as simple as possible, and
- follow best practices on the presentation layer for responsive tables.
Field modeling with Rumsfeld: Known unknowns in your content
I love saying the phrase “modeling ambiguity”. It has a nice mouth feel and its a lot nicer than saying “nobody knows all the details just yet”. I used to say this phrase a lot when I was building database schemas from scratch for applications without frameworks, yuck. The reality of that phrase hurt a lot more back then. Well, thank goodness those dark days are gone. I haven’t had to pull this phrase out all that often with Drupal especially given all of the options that a site-builder has at their finger-tips for multi-value fields, field collections, field groups, field formatters and the powerful context surfacing and evaluation from CTools. However, my old friend reared his ugly head on this problem, and it was just in the nick of time.
Through our discovery phase we uncovered a number of similar fields for several content types. The fields had a heading, with one or more tables. Each table had two columns with one or more rows and a header. Each header had two column headings which may or may not have specific and unique headings per table. Table content had light formatting such as bolds, italics, bullets, and underlines, as well as html links.
In the end it looked something like this – desktop on the left and mobile on the right:
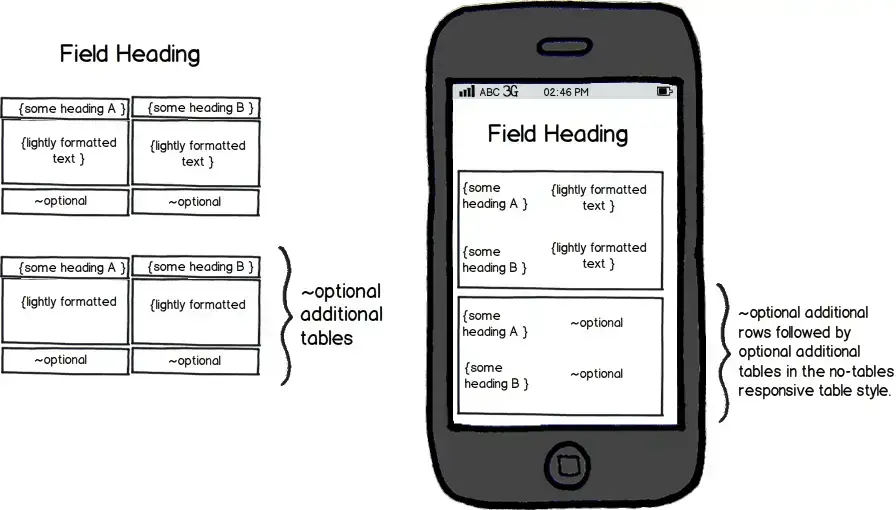
You can have anything you want… for a price
The real problem in all of this was that each time we thought we had nailed down when a particular instance of this field model had a particular set of these variations — another survey of the actual content demonstrated that it was a little different. This is where all that experience with “modeling ambiguity” came in handy. I knew from experience that we could accommodate all of those variations. I knew that while it would be nice, we really didn’t need to know all of the variations before hand. So far that is a pretty rosy picture.
Ah, but I also knew that with ambiguity comes a price. Usually a developer’s blood, sweat, and tears and sometimes a site’s users. Things get complex quickly when you don’t have a lot of things nailed down. You have to think through all of the options and provide ways for contributors to self select at entry time. Both of those can cause pain. I brainstormed a number of ways we might try and accommodate this variability programmatically but I knew it was going to take some time to get all the pieces in place. Since time was a real conce\r\n \there were really two options – create a fast solution that would almost certainly require rework and a lot of band aids but enable quicker entry or step back and create a more novel solution that was truly flexible. Both the client and I agreed that a longer term, flexible solution was in the best interest of the site, timely delivery, and cost.
So I worked backwards from the most complex combination of all of these elements and understood that content contributors would ultimately need to:
- add or remove any number of tables beneath a heading
- allow editable headers on a per table basis with default column headers
- add or remove any number of rows to each table,
- utilize a wysiwyg editor to manage light formatting for each table cell
Scaling with Variability
The obvious choice for tabular data is a table field, right? Right, er, no, not here. Don’t get me wrong, its a great solution for most tabular data needs, please use it. However, it didn’t hit the right notes here. Mainly because it simply doesn’t scale with variability. This is another important concept in successfully modeling ambiguity. “Scaling with variability” means that you should only introduce the additional complexity of handling the variations when needed. With all of the fields set as table fields there is no more-or-less difficult version, it is tables all of the time. Its not particularly flexible for rich editing, nor the heading variability, and to top it off, storage for table fields is fairly unique, which means there would certainly be data migration if the fields needed to be modified further when something new comes up or if no further complexity is introduced to some instances – there is no opportunity to devolve into a simpler state.
What we were really looking for was a nested multi-value field structure that could withstand on the fly changes. Significant field type changes are often disabled after there is data in a field but what we were relying on in this case is that the gradual process of content entry would reveal the need for these variations on particular instances of this field in the content types. So, what field type comfortably accepts a single or delta value without significantly altering the storage? What field type accommodates a multi-field grouping approach? What multi-field type can nest inside itself? What options do we have for rich editing experiences for the table cells?
Arriving at a Model
The field model that answered all of these questions looked something like this:
Field Group {
Field Collection for Table (1 or more / set to 1 initially) {
Header 1 - text field (provided with default heading values)
Header 2 - text field (provided with default heading values)
Field Collection for Table Data (1 or more / set to 1 initially) {
Row data 1 - text long (w/ WYSIWYG editing)
Row data 2 - text long (w/ WYSIWYG editing)
}
}
}
How it works
Let’s discuss how this structure works. The field group is the parent structure which will accommodate the field heading for all tables below. Then we have our nested field collection structure – one field collection that contains another field collection as a child. The first field collection structure allows us to have multiple or single tables underneath the heading and the second field collection gives us multiple or single rows of table data for the parent table field collection. By default we’d start with the simplest configuration of a single table and a single row value which results in a very plain content entry experience. The Row data columns are text fields with wysiwyg field editors allowing our content entry team access to light formatting options with familiar tools. Additionally, if the fields change significantly we have a little more flexibility from the storage perspective. Our variable table headings can be accounted for in the text header 1 and header 2 fields.
The nested field collection approach lets us leverage the strengths of individual field types editing interfaces and their storage. It also gives us the flexibility to add in the option for a multi-value field only when needed. When not in play, as a single value, each field looks just like a single WYSIWYG text field. If at any point during the content entry a content contributor discovers that a particular instance of this field needs to have multiple tables or multiple rows we can enable that variation without fear of having to reroll the field. We simply make tht change on the content type configuration screen. If we need a single multiple row table we can do that, if we need multiple tables with multiple rows with default or empty headings that are required we can do that too. Its a much more configurable solution that lets us dial each instance in at its required complexity.
Hopefully I’ve given you some tools and terms to think about the next time you need to model ambiguity. In the next part of this two part series we’ll take a look at how we translated this field structure into responsive table content with a “no-tables” approach.
Read Part 2 of this post here.
Making the web a better place to teach, learn, and advocate starts here...
When you subscribe to our newsletter!